Target Triple不仅仅是字符串
参考文章

交叉编译
当我们开发目标是一个嵌入式设备时,便需要在PC机上编译出能在该嵌入式设备上运行的可执行文件,这里编译主机与目标运行主机不是同一个设备,那么该过程就称为交叉编译;
现代编译器(特别是基于 LLVM 的 Clang/Rustc 和 Go 编译器)本质上就是交叉编译器。后续我将会以这些现代编译器为例子展开:
Target Triple
程序编译的四个主要步骤是预处理(Pre-Processing)、编译(Compiling)、汇编(Assembling)和链接(Linking),将源代码(如.c文件)转化为最终可执行文件(如.exe或a.out)的过程。这四个步骤依次处理,前三步由编译器完成,最后一步由链接器完成,将代码、库文件等合并。
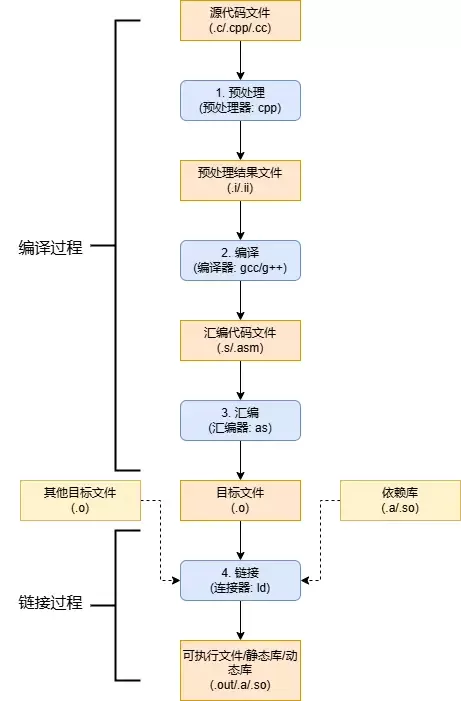
在编译的四个步骤中,“编译”和“汇编”阶段是目标三元组信息发挥作用的核心。它告诉编译器和汇编器要生成哪种特定架构和操作系统的机器码,从而实现跨平台编译(交叉编译),即在一个平台上生成可以在另一个不同平台上运行的代码。
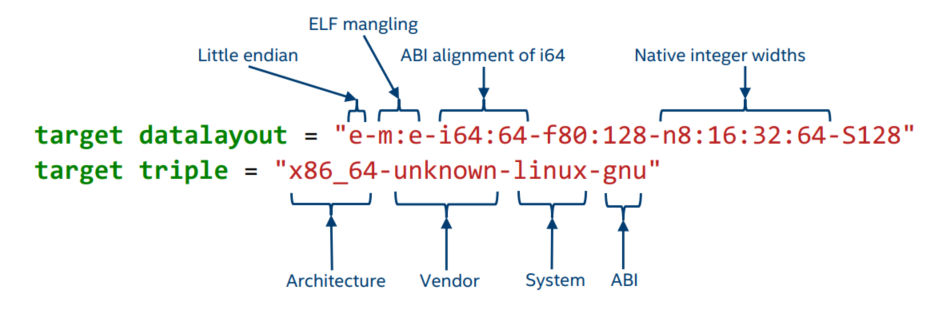
在编译器技术(尤其是 LLVM 和 GNU 工具链)中,Target Triple 是交叉编译的坐标系。它不仅是一串用于标识目标平台的字符串,更是编译器后端(Backend)、汇编器(Assembler)和链接器(Linker)选择正确代码生成策略的配置清单。
虽然名字叫“Triple”(三元组),但实际上他包含 四个 字段:
Target Triple 有“标准答案”吗?
严格来说,没有。
Target Triple 并不存在一个像 IANA 那样的“官方注册表”,也没有哪个标准组织来统一分配这些名字。你在不同工具里看到的 triple,更多来自历史惯例 + 主流实现的事实标准。
今天几乎所有“现代原生编译器”都绕不开 LLVM(Clang/Rust/Swift/NVCC/ICC 等的某一段都在用它),因此 LLVM 的命名体系基本成了事实标准;但你仍然会经常遇到GCC/发行版工具链延续的 GNU triplet 命名(例如 gcc -dumpmachine 的输出),两者看起来很像、但细节常常不一致。
GNU triplet vs LLVM triple:同源但不完全同名
Target triple(以及“明明四段却叫 triple”)的历史包袱,很大一部分来自 GCC 时代的交叉编译方式:传统上是“一个目标一套工具链二进制”,工具名本身带着前缀:
aarch64-linux-gnu-gcc/aarch64-linux-gnu-ld/aarch64-linux-gnu-as
也就是说,triple 最早更像是“工具链二进制的命名前缀”,被 autoconf 这类构建系统广泛依赖;这也解释了为什么它会长得像 <arch>-<vendor>-<os> 这种“分类字符串”。
LLVM/Clang 则更像“一把万能枪”:同一个 clang 二进制包含多个后端,通过 --target=... 选择目标。此时 triple 不再是可执行文件名的一部分,但命名体系仍然被保留下来。
所以你会看到类似现象:
- GCC 可能报告:
x86_64-linux-gnu - Clang/Rust 更常见:
x86_64-unknown-linux-gnu
它们往往可以互相“猜得出来”,但不要把它当作完全一致的规范。
Target Triple 的四个字段
字段一:Architecture (架构)
这是最基础的物理层描述,决定了指令集架构 (ISA)、字节序 (Endianness) 和位宽 (Bitness)。
- 常见值:
x86_64,aarch64(ARM64),arm(ARMv7),riscv64,wasm32,thumbv6m(Cortex-M0)。 - 隐含信息:
- 字节序:
mips通常指大端,mipsel指小端。 - 指令集模式: 如
arm可能指代传统的 32位 ARM 指令,而thumb指代 Thumb 指令集(常见于微控制器)。
关于“架构名”的一个大坑:别名与版本号
真实世界里,架构名经常存在“别名/俗称”,导致你在不同文档、包名、工具输出里看到的名字不一样:
x86_64也常被叫作amd64(尤其在 Go、Debian/Ubuntu 包名里)aarch64也常被叫作arm64(同样常见于 Go/发行版生态)mipsel有时也会以mipsle的形式出现(同样表达小端)
另外,ARM/Thumb 家族经常把“版本/配置”直接编码进架构字段(例如 armv7r, thumbv7em, thumbv6m),这在工程上很实用,但也意味着:
- triple 里的
armv7.../thumbv...并不是-mcpu=cortex-...的替代品 - 更细粒度的 CPU/指令扩展选择仍然通常通过
-mcpu/-march/-mattr完成
字段二:Vendor (厂商)
标识制造该计算平台的厂商。
- 历史遗留: 在早期 Unix 工作站时代,这个字段很重要(如
sun,hp,ibm)。 - Linux/BSD: 通常无关紧要,常被标记为
unknown或pc(如x86_64-unknown-linux-gnu)。在很多配置中,这个字段甚至可以被省略。 - Apple: 必须指定
apple(如aarch64-apple-darwin),这会触发编译器针对 Apple 平台的特殊处理(如 Mach-O 格式)。 - Windows: 常出现
pc或w64。
字段三:Operating System (操作系统)
这一段经常被叫作 OS,但更准确的叫法是 system:它不仅仅代表“操作系统名称”,也可以代表更宽泛的平台系统。
它会影响(不同工具实现侧重点不同,但总体如此):
- 可执行/目标文件格式:ELF、PE/COFF、Mach-O
- 异常处理模型:例如 Windows 上的 SEH
- 链接与重定位细节:默认链接器行为、重定位类型等
- 预定义宏:例如
__linux__、_WIN32这类条件编译入口
- 常见值:
linux,windows,darwin(macOS/iOS),freebsd。 - 特殊值
none: 用于裸机开发 (Bare Metal)。例如thumbv6m-none-eabi表示在一个没有操作系统的 ARM Cortex-M0 芯片上运行,这意味着编译器不能生成任何系统调用代码(如open,read),且必须依赖独立的运行时。
字段四:Environment (环境 / ABI)
这是最关键但也最容易被忽视的字段。它定义了 ABI (应用二进制接口) 和 C标准库 (LibC) 的实现。如果这个字段不匹配,链接一定会失败,或者程序运行时崩溃。
- Linux 常见环境:
gnu:使用 glibc。这是大多数桌面 Linux (Ubuntu, Fedora) 的标准。musl:使用 musl libc。常用于 Alpine Linux 或构建静态链接的二进制文件(体积小,移植性好)。android:使用 Bionic libc。
- ARM 专用环境:
eabi:Embedded ABI。使用软件模拟浮点运算 (Soft Float) 或通用的寄存器规则。eabihf:Embedded ABI Hard Float。显式调用硬件浮点单元 (FPU),参数通过 FPU 寄存器传递。注意:eabi和eabihf的二进制文件通常不兼容。
- Windows 专用环境:
msvc:使用 Microsoft Visual C++ 运行时 (MSVC CRT)。生成的程序像原生 Windows 程序。gnu:使用 MinGW (Minimalist GNU for Windows)。试图在 Windows 上模拟 GNU 环境。
Target Triple 到底控制了编译器的什么?
当在 clang 或 rustc 中指定 --target=arm-unknown-linux-gnueabihf 时,编译器内部发生了这些变化:
| 控制层面 | 实际影响 (Under the hood) |
|---|---|
| 代码生成 (Codegen) | 选择 ARM 指令集后端;因为是 hf (Hard Float),生成的汇编会使用 vadd.f32 等 FPU 指令,而不是调用 __aeabi_fadd 函数。 |
| 寄存器使用 (Calling Convention) | 函数调用时,前几个参数是放在 r0-r3 还是放在栈上?浮点参数是放在通用寄存器还是 s0-s1?Triple 决定了这一契约。 |
| 数据布局 (Data Layout) | long double 是 64位还是 128位?结构体如何对齐?指针的宽度是多少? |
| 预定义宏 (Pre-processor) | 编译器会自动注入 #define __linux__, #define __ARM_ARCH_7A__ 等宏,供源代码中的 #ifdef 使用。 |
| 链接器行为 (Linker) | 寻找 crt0.o (启动文件) 的位置;决定链接 libc.so 还是 libSystem.dylib。 |
C语言交叉编译示例
前面我们把 triple 拆成了“四段”,也说明了它会影响 codegen、宏、数据布局、调用约定和链接行为。但这些讨论仍然偏“概念”。接下来用一个最小的 C 示例把它落到实处:同一份源码只改一个 --target=...,你会直观看到预定义宏分支改变、以及在链接阶段为什么需要 sysroot/目标 libc。
1. 为什么选择 Clang?
可能你会很熟悉
- GCC (GNU Compiler Collection):如果你要编译 ARM 程序,你需要安装专门的
aarch64-linux-gnu-gcc;如果要编译 MIPS,又得装mips-linux-gnu-gcc。还是很麻烦的。 - Clang (LLVM):Clang 原生支持所有架构,你只需要安装一个标准版
clang,就可以通过--target参数切换生成任意平台的代码。这就方便很多了
2. 准备示例代码
我们需要一个能体现“架构差异”的代码。最直接的方法是利用预定义宏进行条件编译。
utils.h (头文件)
const char* get_arch_name(void);
int square(int x);
utils.c (实现架构检测)
int square(int x) {
return x * x;
}
const char* get_arch_name(void) {
// 这里的宏是由编译器根据 --target 参数自动注入的
return "AArch64 (ARM 64-bit)";
return "x86_64 (Intel/AMD 64-bit)";
return "ARM (32-bit)";
return "Unknown Architecture";
}
main.c (主程序)
int main(void) {
// 1. 打印当前架构名称(由编译时的宏决定)
const char* arch = get_arch_name();
printf("Application running on: %s\n", arch);
// 2. 简单的函数调用
int val = 12;
printf("Square of %d is %d\n", val, square(val));
// 3. 打印类型大小,演示不同架构可能的数据模型差异
// (注意:x86_64 和 aarch64 上 long 通常都是 8 字节,但如果是 32 位 ARM 则会是 4 字节)
printf("Size of long: %zu bytes\n", sizeof(long));
return 0;
}
3. 实战:本地编译 vs 交叉编译
3.1 本地编译 (Host Compilation)
首先在PC机(通常是 x86_64 Linux)上编译并运行。
# 编译 |
输出:
Application running on: x86_64 (Intel/AMD 64-bit)
Square of 12 is 144
Size of long: 8 bytes
程序正确识别了当前环境。
3.2 交叉编译 (Cross Compilation)
现在,我们将目标设定为 AArch64(即 ARMv8 架构的 64 位运行状态,广泛用于 Android 手机、树莓派等)。
前置要求:链接阶段仍需要目标平台的标准库(libc)。如果你在 Linux 上,可能需要安装
gcc-aarch64-linux-gnu包来提供 sysroot 及其 C 库。
# --target 指定了目标架构三元组 |
3.3 验证产物
尝试在 x86 机器上运行这个新生成的程序:
./app_aarch64 |
输出:
bash: ./app_aarch64: 无法执行二进制文件: 可执行文件格式错误
这是预期的失败!因为你的 x86 CPU 根本读不懂 ARM64 的指令集。我们可以用 file 命令查看它的真身:
file app_aarch64 |
输出:
./app_aarch64: ELF 64-bit LSB pie executable, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=335af0832b262d0f3ddee123a799f7e4ed9704a6, for GNU/Linux 3.7.0, not stripped
4. 深入跨平台编译幕后:
当我们敲下 clang main.c -o app 时,看似一步到位的操作,背后其实经历了四个独立的阶段:预处理、编译、汇编和链接。
第一阶段:预处理 (Preprocessing)
任务:文本替换。展开 #include,处理 #define 和 #ifdef。
输入/输出:.c 源码 → .i 预处理文件 (纯文本)
这是交叉编译差异产生的起点。
- 命令:
clang --target=aarch64-linux-gnu -E utils.c -o utils.i
- 关键点:
- 宏注入:编译器根据 Target 注入宏(如
__aarch64__)。这决定了代码走哪个分支。 - 头文件路径:
#include <stdio.h>会去--sysroot指定的目录找目录板子的头文件,而不是本机的/usr/include。
- 宏注入:编译器根据 Target 注入宏(如
第二阶段:编译 (Compilation)
任务:将 C 语言“翻译”成汇编代语言。
输入/输出:.i 预处理文件 → .s 汇编文件 (文本格式的 CPU 指令)
这里决定了程序的指令集。
- 命令:
clang --target=aarch64-linux-gnu -S utils.c -o utils.s
- 对比:
x86 使用imull(CISC),而 ARM64 使用mul(RISC, 定长指令)。注意:如果在 C 代码里写了 x86 专用的内联汇编
asm("..."),这一步会报错。
第三阶段:汇编 (Assembly)
任务:将汇编指令(文本)翻译成机器码(二进制)。
输入/输出:.s 汇编文件 → .o 目标文件 (ELF 二进制)
此时产生的文件虽然是二进制,但还不能运行。
- 命令:
clang --target=aarch64-linux-gnu -c utils.s -o utils.o
- 关键点:
产生的目标文件会被打上ARM aarch64的标签。汇编器 (Assembler) 必须是支持目标架构的。
第四阶段:链接 (Linking)
任务:打包。将多个 .o 文件以及系统库(如 libc)合并成最终的可执行文件。
输入/输出:.o 文件 + .a/.so 库文件 → 可执行文件
这是交叉编译最容易报错的阶段。
- 命令:
# 不建议直接调用 ld,通常用 clang 驱动 linker
clang --target=aarch64-linux-gnu main.o utils.o -o app_aarch64 - 关键点:
- 符号解析:将
main.o中的square调用地址指向utils.o中的实现地址。 - 库依赖:链接器必须找到目标平台(AArch64 版)的
libc.so。如果找不到或找到了 x86 版的库,都会报错(cannot find -lc或incompatible format)。
- 符号解析:将
Rust 语言交叉编译示例:从 C 到 Rust
Rust 的交叉编译体验通常比 C 更顺畅,因为 Cargo 和 rustup 屏蔽了许多底层细节,但在链接阶段,它依然依赖于系统链接器。
1. 为什么选择 Rust 工具链?
与 C 语言世界中 GCC (一个靶子一把枪) 和 Clang (一把万能枪) 的区别类似,Rust 从设计之初就采用了 LLVM 作为后端,因此它天生就像 Clang 一样支持多架构编译。
- rustup: 管理“工具链”和“标准库”。你不需要重新下载编译器,只需要下载目标平台的标准库 (std/core)。
- cargo: 构建工具。通过
--target参数协调编译过程。
2. 准备示例代码
这里我们复刻了 C 语言版本的逻辑,文件结构也类似。
src/utils.rs (对应 C 的 utils.c/h)pub fn square(x: i32) -> i32 {
x * x
}
pub fn get_arch_name() -> &'static str {
// cfg! 宏在编译期解析,类似于 C 的 #if defined(...)
if cfg!(target_arch = "aarch64") {
"AArch64 (ARM 64-bit)"
} else if cfg!(target_arch = "x86_64") {
"x86_64 (Intel/AMD 64-bit)"
} else {
"Unknown Architecture"
}
}
src/main.rs (对应 C 的 main.c)mod utils;
fn main() {
// 1. 打印当前架构名称(由编译时的 cfg! 决定)
let arch = utils::get_arch_name();
println!("Application running on: {}", arch);
// 2. 简单的函数调用
let val = 12;
println!("Square of {} is {}", val, utils::square(val));
// 3. 打印类型大小
// Rust 的 usize/isize 类似于 C 的 long/size_t,其大小取决于目标平台的指针宽度
println!("Size of usize: {} bytes", std::mem::size_of::<usize>());
}
3. 实战:本地编译 vs 交叉编译
3.1 本地编译 (Host Compilation)
cargo build --release |
输出:
Application running on: x86_64 (Intel/AMD 64-bit)
Square of 12 is 144
Size of usize: 8 bytes
3.2 交叉编译 (Cross Compilation)
目标同样设定为 AArch64 Linux。
在 C 语言中,我们需要手动确保 sysroot 存在。在 Rust 中,我们首先需要安装目标平台的标准库。
第一步:安装目标架构的标准库
# 这相当于给你的编译器装上了“说 AArch64 语”的能力 |
第二步:编译
cargo build --release --target aarch64-unknown-linux-gnu |
注意:链接错误
如果你在 Linux 主机上运行上述命令,可能会通过编译(Compiling),但在链接(Linking)阶段失败。
报错通常是:linker 'cc' not found或mod.rs error: linking with cc failed: exit status: 1。原因:Rust 自身不带链接器,它默认调用系统的
cc(通常是 gcc) 来链接。而系统的gcc是 x86 的,无法链接 ARM 的代码。解决方法:你需要告诉 Cargo 使用正确的链接器(如
aarch64-linux-gnu-gcc)。
这通常在.cargo/config.toml中配置:
linker = "aarch64-linux-gnu-gcc"
第三步:检查产物
file target/aarch64-unknown-linux-gnu/release/cross-compilation-rust-example |
输出:
target/aarch64-unknown-linux-gnu/release/cross-compilation-rust-example: ELF 64-bit LSB pie executable, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=9e677d93aacf3092ddefc5b0bb02cacdea74d27f, for GNU/Linux 3.7.0, not stripped
结尾
软件工程中一个常见现象:实用主义胜过完美设计。作为工程师,我们不需要去标准化,只需要查表和配置即可
就像Linux内核版本命名也并不是完全根据SemVer标准来的,由于编辑器历史很长,更多的需要考虑实际情况,降低下游用户的依赖维护成本,保留大家认可的命名习惯,这才是比任何八股的标准都更值得信赖的承诺
Target Triple系统虽然混乱、不一致,但通过LLVM等主流工具的广泛采用,已成为跨平台编译的实际标准。
 微信打赏
微信打赏